Seeing the World: A Beginner's Guide to CNNs using PyTorch
- How Computers See Images
- The Problem with Traditional Neural Networks for Images
- Introducing Convolutional Layers
- Essential CNN Operations: Padding and Pooling
- Building a CNN Architecture
- Activation Functions for CNNs
- Handling Image Data in PyTorch
- Data Augmentation: Making Your Model Robust
- Training Your CNN
- Evaluating Your CNN
- Fighting Overfitting in CNNs
- Modern CNN Architectures
- Conclusion
Seeing the World: A Beginner’s Guide to Convolutional Neural Networks using PyTorch
Welcome to the fascinating world of deep learning! If you’ve ever wondered how computers can recognize objects in images, distinguish between different types of clouds, or even power automated passport control systems, you’re about to uncover one of the key technologies behind it: Convolutional Neural Networks (CNNs).
These powerful neural networks are specifically designed to handle image data and have revolutionized computer vision over the past decade.

How Computers See Images
Before diving into CNNs, let’s understand how computers perceive images. Digital images are made up of tiny squares called pixels.
In a grayscale image, each pixel holds a numerical value representing a shade of gray, typically from 0 (black) to 255 (white). For color images, each pixel usually has three numerical values representing the intensity of Red, Green, and Blue (RGB) channels.
These values are organized into a tensor (like a multi-dimensional array) with dimensions for:
- Color channels (e.g., 3 for RGB)
- Height (number of pixel rows)
- Width (number of pixel columns)
The Problem with Traditional Neural Networks for Images
You might recall that traditional neural networks use linear layers where every input neuron is connected to every output neuron (fully connected networks). This architecture works well for data with a small number of features, but images pose a significant challenge.
Consider a simple grayscale image of 256×256 pixels:
- This single image has over 65,000 input features
- If you used a linear layer with even a modest 1,000 neurons, you’d end up with over 65 million parameters just in that first layer
- For color images, this number jumps significantly
Such a large number of parameters creates multiple problems:
- Training becomes extremely slow
- The risk of overfitting increases dramatically
- Most critically, linear layers don’t inherently understand spatial patterns
If a linear layer learns to detect a feature, like a cat’s ear, in one corner of an image, it won’t automatically recognize the same ear if it appears in a different location. Images are all about patterns and their spatial relationships!
Introducing Convolutional Layers
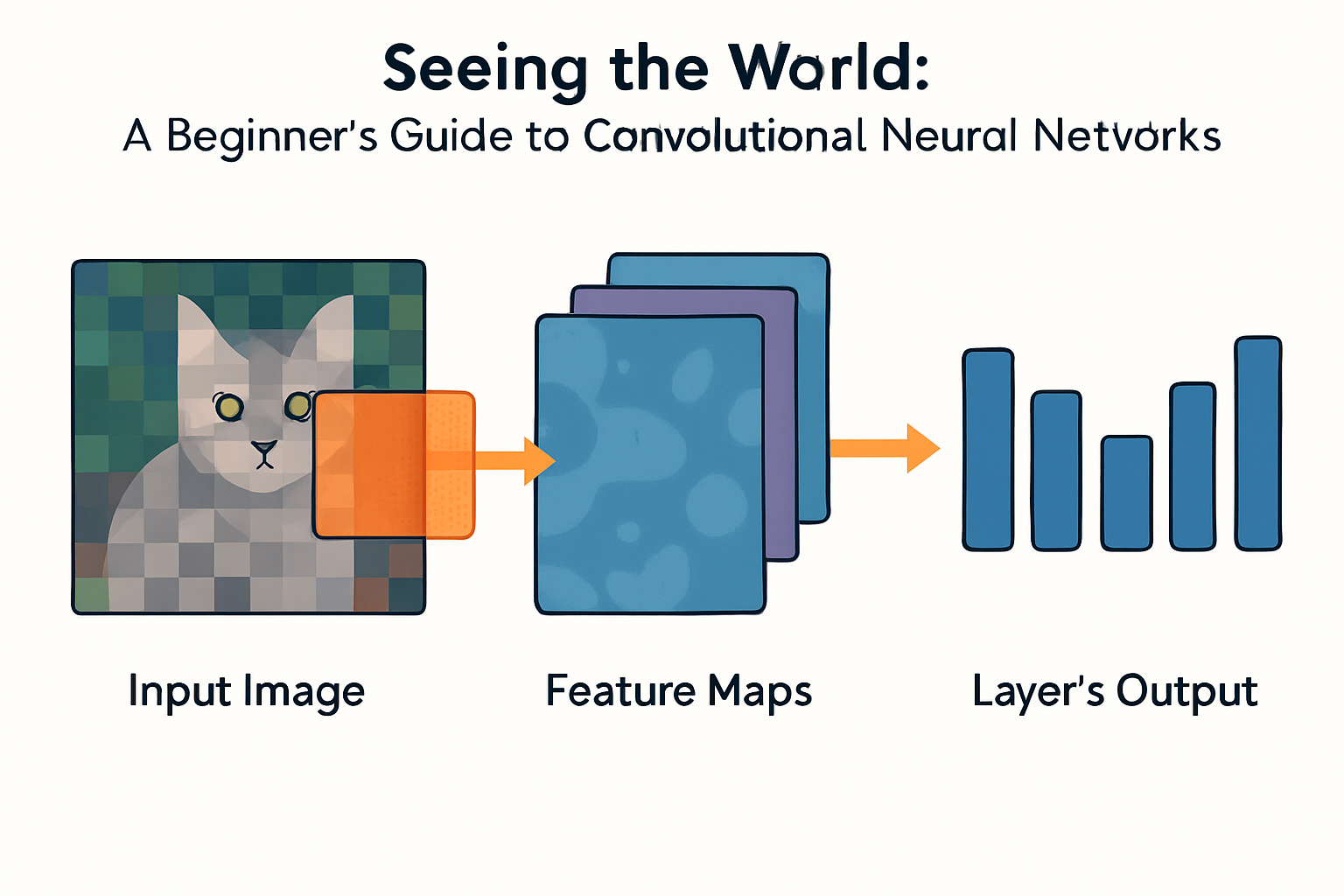
This is where convolutional layers come in. CNNs use convolutional layers as a much more efficient and effective way to process images.
Instead of connecting every input pixel to every neuron, convolutional layers use small grids of parameters called filters (or kernels). These filters slide over the input image (or a feature map from a previous layer), performing a convolution operation at each position.

The convolution operation is essentially a dot product between the filter and a patch of the input data covered by the filter. The results of this sliding operation at each position are collected to create a feature map.
Key advantages of convolutional layers:
- Parameter efficiency: They use far fewer parameters than linear layers for images
- Location invariance: If a filter learns to detect a pattern, it can recognize that pattern regardless of its location in the input
- Hierarchical feature learning: Early layers can detect simple features like edges and textures, while deeper layers combine these to detect complex features like shapes and objects
In PyTorch, you define a convolutional layer using nn.Conv2d. You specify the number of input and output feature maps (or channels) and the kernel size:
# 3 input channels (RGB), 32 output feature maps, 3x3 filter size
conv_layer = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3)Essential CNN Operations: Padding and Pooling
Two other common operations in CNNs are zero padding and pooling.
Zero Padding
Often, zeros are added around the borders of the input before applying a convolutional layer. This technique helps:
- Control the spatial dimensions of the output
- Ensure that pixels at the border of the image are treated equally
- Prevent information loss at the edges
In PyTorch, you can specify padding using the padding argument in nn.Conv2d:
# Add 1 pixel of padding around the borders
conv_layer = nn.Conv2d(
in_channels=3,
out_channels=32,
kernel_size=3,
padding=1
)Max Pooling
This operation typically follows convolutional layers. A non-overlapping window slides over the feature map, and at each position, the maximum value within the window is selected.

Using a 2×2 window, for instance, halves the height and width of the feature map. Max pooling helps to:
- Reduce the spatial dimensions
- Decrease the number of parameters and computational complexity
- Make the model more invariant to small shifts and distortions
In PyTorch, you implement max pooling with nn.MaxPool2d:
# 2x2 max pooling
pool_layer = nn.MaxPool2d(kernel_size=2)Building a CNN Architecture
A typical CNN for image classification has two main parts: a feature extractor and a classifier.
1. Feature Extractor
This part is usually composed of repeated blocks of:
- Convolutional layers
- Activation functions
- Max pooling layers
Its purpose is to process the raw pixel data and extract relevant features.
2. Classifier
This part takes the flattened output of the feature extractor (which is now a vector) and passes it through one or more linear layers to make the final prediction. The output dimension of the last linear layer matches the number of target classes.
Here’s a simple CNN architecture in PyTorch:
import torch
import torch.nn as nn
class SimpleCNN(nn.Module):
def __init__(self, num_classes=10):
super().__init__()
# Feature extractor
self.features = nn.Sequential(
# First block
nn.Conv2d(in_channels=3, out_channels=16,
kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
# Second block
nn.Conv2d(in_channels=16, out_channels=32,
kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
# Third block
nn.Conv2d(in_channels=32, out_channels=64,
kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
# Classifier
self.classifier = nn.Sequential(
# Assuming input image was 32x32,
# after 3 pooling layers it's 4x4
nn.Flatten(), # Flatten the 4x4x64 feature maps
nn.Linear(4 * 4 * 64, 128),
nn.ReLU(),
nn.Linear(128, num_classes)
)
def forward(self, x):
x = self.features(x)
x = self.classifier(x)
return xActivation Functions for CNNs
Like other neural networks, CNNs need nonlinearity to learn complex patterns. Activation functions are crucial for this.
For the hidden layers within the feature extractor, common choices include:
ReLU (Rectified Linear Unit)
- Outputs the input value if positive, and zero otherwise
- Avoids the vanishing gradients problem for positive inputs
- Available as
nn.ReLU - The most common choice for CNNs
Leaky ReLU
- A variation of ReLU that outputs a small non-zero value for negative inputs
- Prevents the “dying neuron” problem sometimes seen with standard ReLU
- Available as
nn.LeakyReLUwith anegative_slopeargument
For the output layer:
- Sigmoid is typically used for binary classification
- Softmax is used for multiclass classification
Handling Image Data in PyTorch
To train a CNN, you need to prepare your image data. PyTorch’s torchvision library is very helpful here.
With a directory structure where each class has its own folder, you can use ImageFolder to create a dataset:
import torch
import torchvision
import torchvision.transforms as transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
# Define transformations for images
image_transforms = transforms.Compose([
transforms.ToTensor(), # Convert PIL Image to PyTorch Tensor
transforms.Resize((128, 128)) # Resize image to 128x128
])
# Create a dataset using ImageFolder
# Assumes data is in a directory structure like:
# cloud_train/
# ├── class1/
# │ └── img1.jpg
# └── class2/
# └── img2.jpg
train_dataset = ImageFolder(root='cloud_train',transform=image_transforms)
# Create a DataLoader for efficient batching and shuffling
train_loader = DataLoader(train_dataset,batch_size=32, shuffle=True)Data Augmentation: Making Your Model Robust
A powerful technique for image data, especially to combat overfitting, is data augmentation. This involves applying random transformations to the training images, such as:
- Random Rotation: Exposes the model to objects at different angles
- Horizontal Flip: Simulates different viewpoints
- Color Jitter: Simulates different lighting conditions

These transformations artificially increase the size and diversity of your training set, making the model more robust to variations found in real-world images.
Implementation in PyTorch is straightforward:
train_transforms = transforms.Compose([
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomRotation(degrees=15),
transforms.ColorJitter(brightness=0.1, contrast=0.1),
transforms.ToTensor(),
transforms.Resize((128, 128))
])
# Data augmentation only for training data, not validation/test
train_dataset = torchvision.datasets.ImageFolder(
root='cloud_train',
transform=train_transforms
)Remember to choose augmentations that are appropriate for your specific task. Some augmentations could change the meaning of the image (e.g., flipping a “W” vertically might make it look like an “M”).
Training Your CNN
Training a CNN involves the standard deep learning training loop:
- Define a loss function (e.g.,
nn.CrossEntropyLossfor multiclass classification) - Choose an optimizer (e.g.,
optim.Adamoroptim.SGD) - Loop through multiple epochs (full passes through the training data)
- Inside each epoch, process batches of data from the data loader
Here’s a complete training loop:
import torch.optim as optim
# Instantiate model, loss function, and optimizer
model = SimpleCNN(num_classes=10)
criterion = nn.CrossEntropyLoss() # For multiclass classification
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam optimizer
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# Training loop
num_epochs = 10
for epoch in range(num_epochs):
model.train() # Set model to training mode
running_loss = 0.0
for inputs, labels in train_loader:
# Move data to the same device as model
inputs, labels = inputs.to(device), labels.to(device)
# Zero the parameter gradients
optimizer.zero_grad()
# Forward pass
outputs = model(inputs)
loss = criterion(outputs, labels)
# Backward pass and optimize
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {running_loss/len(train_loader):.4f}")Evaluating Your CNN
Evaluating your model’s performance is crucial. Data is typically split into training, validation, and test sets.
Key evaluation metrics for classification include:
- Accuracy: The overall frequency of correct predictions
- Precision: The fraction of correct positive predictions among all positive predictions
- Recall: The fraction of all positive examples that were correctly predicted
- F1 Score: The harmonic mean of precision and recall
Here’s an evaluation loop:
# Evaluation loop
model.eval() # Set model to evaluation mode
correct = 0
total = 0
with torch.no_grad(): # Disable gradient calculation
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
# Forward pass
outputs = model(inputs)
# Get predicted class
_, predicted = torch.max(outputs, 1)
# Update statistics
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f"Test Accuracy: {accuracy:.2f}%")Tracking training loss vs. validation loss (and accuracy) is key to detecting overfitting; if training loss keeps decreasing but validation loss starts to rise, your model is overfitting.
Fighting Overfitting in CNNs
Besides data augmentation, other strategies to fight overfitting include:
1. Dropout
Randomly deactivating a fraction of neurons during training, preventing over-reliance on specific features:
nn.Conv2d(32, 64, 3),
nn.ReLU(),
nn.Dropout(p=0.25), # 25% dropout after activation
nn.MaxPool2d(2)2. Batch Normalization
Normalizing the activations of the previous layer to speed up training and add some regularization:
nn.Conv2d(32, 64, 3),
nn.BatchNorm2d(64), # Batch normalization after convolution
nn.ReLU()3. Weight Decay
Adding a penalty to the loss function to encourage smaller weights:
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-4)4. Early Stopping
Monitoring validation performance and stopping training when it starts to degrade.
Modern CNN Architectures
While our example used a simple CNN, many powerful architectures have been developed:
- VGG: Uses very small 3×3 filters with many layers
- ResNet: Introduces skip connections to help train very deep networks
- Inception/GoogLeNet: Uses parallel paths with different filter sizes
- EfficientNet: Scales depth, width, and resolution together for efficiency
Many of these are available pre-trained in torchvision.models and can be used for transfer learning.
Conclusion
CNNs are the backbone of modern computer vision. By understanding how they process images through convolutional filters, pooling, and activation functions, you’ve taken a significant step in building powerful models that can truly “see” the world.
The key insights to remember:
- CNNs use sliding filters to detect patterns regardless of their location
- They build hierarchical representations from simple features to complex ones
- Techniques like pooling and padding help control spatial dimensions
- Data augmentation and regularization techniques like dropout are essential for robust models
Now it’s time to experiment and build your own CNN models! Whether you’re interested in image classification, object detection, or more advanced tasks like image segmentation, the principles covered here will serve as your foundation.
